What's DeepSeek Coder: Revolutionizing Code Automation In Latenode
페이지 정보
작성자 K****** 댓글 0건 조회 16 회 작성일 25-02-03 12:32본문
 Unsurprisingly, many customers have flocked to deepseek ai china to entry superior models at no cost. Perplexity, an AI-powered search engine, lately incorporated R1 into its paid search product, allowing customers to experience R1 without utilizing DeepSeek’s app. Let Deepseek’s AI handle the heavy lifting-so you can concentrate on what issues most. We select a subset of issues from the classes of syntactic and reference errors, as fixing these errors could be assisted by LSP diagnostics. More lately, LivecodeBench has shown that open large language fashions wrestle when evaluated in opposition to recent Leetcode problems. Therefore, so as to strengthen our evaluation, we choose recent issues (after the base model’s knowledge cutoff date) from Leetcode competitions as proposed in LiveCodeBench and use the artificial bug injection pipeline proposed in DebugBench to create additional analysis situations for the check set. As such, we carried out our pipeline with PySpark on Databricks to scale up compute as needed. We discovered that a effectively-defined artificial pipeline resulted in additional correct diffs with less variance in the output space when compared to diffs from users. This transfer provides users with the opportunity to delve into the intricacies of the model, explore its functionalities, and even integrate it into their projects for enhanced AI purposes.
Unsurprisingly, many customers have flocked to deepseek ai china to entry superior models at no cost. Perplexity, an AI-powered search engine, lately incorporated R1 into its paid search product, allowing customers to experience R1 without utilizing DeepSeek’s app. Let Deepseek’s AI handle the heavy lifting-so you can concentrate on what issues most. We select a subset of issues from the classes of syntactic and reference errors, as fixing these errors could be assisted by LSP diagnostics. More lately, LivecodeBench has shown that open large language fashions wrestle when evaluated in opposition to recent Leetcode problems. Therefore, so as to strengthen our evaluation, we choose recent issues (after the base model’s knowledge cutoff date) from Leetcode competitions as proposed in LiveCodeBench and use the artificial bug injection pipeline proposed in DebugBench to create additional analysis situations for the check set. As such, we carried out our pipeline with PySpark on Databricks to scale up compute as needed. We discovered that a effectively-defined artificial pipeline resulted in additional correct diffs with less variance in the output space when compared to diffs from users. This transfer provides users with the opportunity to delve into the intricacies of the model, explore its functionalities, and even integrate it into their projects for enhanced AI purposes.
In actual fact, solely 10% of LSP diagnostic messages in Python tasks on Replit have associated fixes. His experience extends throughout leading IT companies like IBM, enriching his profile with a broad spectrum of software program and cloud projects. Whilst platforms like Perplexity add entry to DeepSeek and claim to have eliminated its censorship weights, the mannequin refused to reply my question about Tiananmen Square as of Thursday afternoon. For example, we will add sentinel tokens like and to indicate a command that needs to be run and the execution output after working the Repl respectively. Following OctoPack, we add line numbers to the input code, LSP error line, and output line diffs. Therefore, following DeepSeek-Coder, we saved the file name above the file content material and did not introduce extra metadata used by other code models, comparable to a language tag. In contrast to the same old instruction finetuning used to finetune code fashions, we didn't use pure language instructions for our code repair mannequin. We exhibit that the reasoning patterns of larger models can be distilled into smaller fashions, leading to better performance in comparison with the reasoning patterns discovered via RL on small fashions. As I highlighted in my weblog publish about Amazon Bedrock Model Distillation, the distillation course of involves training smaller, extra efficient fashions to imitate the behavior and reasoning patterns of the larger free deepseek-R1 model with 671 billion parameters through the use of it as a teacher mannequin.
1e-eight with no weight decay, and a batch dimension of 16. Training for 4 epochs gave the very best experimental performance, in step with earlier work on pretraining the place four epochs are considered optimal for smaller, high-high quality datasets. It's reported that DeepSeek-V3 relies on the best performance of the efficiency, which proves the sturdy efficiency of mathematics, programming and natural language processing. In 2018, when Microsoft launched "A Common Protocol for Languages," Replit started supporting the Language Server Protocol. The paper introduces DeepSeekMath 7B, a big language mannequin that has been pre-skilled on an enormous amount of math-associated knowledge from Common Crawl, totaling 120 billion tokens. We distill a mannequin from synthesized diffs as a result of fixed errors taken directly from person information are noisier than synthesized diffs. We chose numbered Line Diffs as our target format primarily based on (1) the discovering in OctoPack that Line Diff formatting leads to larger 0-shot fix performance and (2) our latency requirement that the generated sequence ought to be as brief as doable.
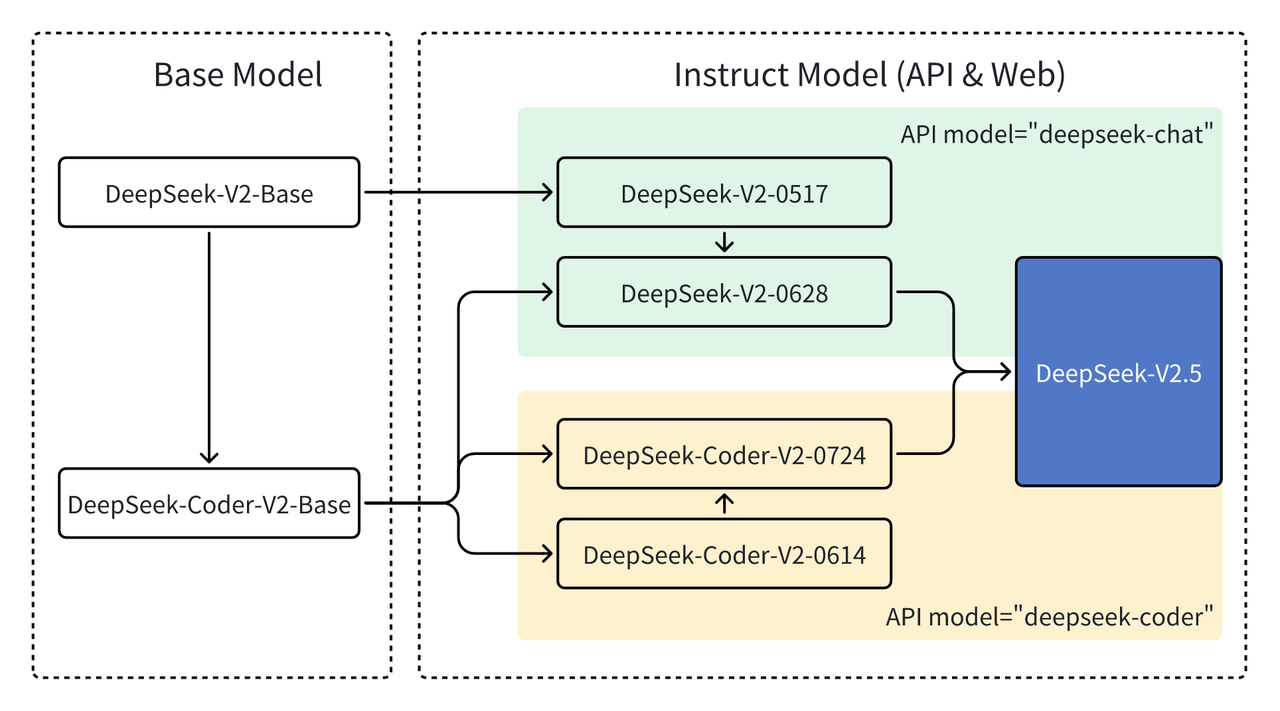 We selected the model dimension of 7B to balance model capabilities with our constraints of inference latency and cost. Look no additional if you want to include AI capabilities in your current React utility. 1. On the DeepSeek homepage, look for the "Login" or "Sign In" button. Deepseek doesn’t simply look on the words in your search. Speed and effectivity: DeepSeek demonstrates quicker response occasions in particular tasks as a consequence of its modular design. We also apply the generated numbered line diffs to the code file with line numbers to make sure that they are often correctly and unambiguously utilized, eliminating samples that can not be applied as a consequence of incorrect line numbers or hallucinated content. We did not detect mode collapse in our audit of the generated data and recommend synthesizing information beginning from real-world states over end-to-finish synthesis of samples. We found that responses are more constantly generated and formatted and, therefore, simpler to parse. We compared Line Diffs with the Unified Diff format and found that line numbers were hallucinated in the Unified Diff each with and without line numbers in the enter. Compared to synthesizing each the error state and the diff, starting from actual error states and synthesizing only the diff is much less prone to mode collapse, since the input characteristic and diff distributions are drawn from the actual world.
We selected the model dimension of 7B to balance model capabilities with our constraints of inference latency and cost. Look no additional if you want to include AI capabilities in your current React utility. 1. On the DeepSeek homepage, look for the "Login" or "Sign In" button. Deepseek doesn’t simply look on the words in your search. Speed and effectivity: DeepSeek demonstrates quicker response occasions in particular tasks as a consequence of its modular design. We also apply the generated numbered line diffs to the code file with line numbers to make sure that they are often correctly and unambiguously utilized, eliminating samples that can not be applied as a consequence of incorrect line numbers or hallucinated content. We did not detect mode collapse in our audit of the generated data and recommend synthesizing information beginning from real-world states over end-to-finish synthesis of samples. We found that responses are more constantly generated and formatted and, therefore, simpler to parse. We compared Line Diffs with the Unified Diff format and found that line numbers were hallucinated in the Unified Diff each with and without line numbers in the enter. Compared to synthesizing each the error state and the diff, starting from actual error states and synthesizing only the diff is much less prone to mode collapse, since the input characteristic and diff distributions are drawn from the actual world.
- 이전글The Hidden Mystery Behind Deepseek 25.02.03
- 다음글8 Tips To Increase Your Ford Fiesta Replacement Key Cost Uk Game 25.02.03
댓글목록
등록된 댓글이 없습니다.

